JS逆向 | WebPack实战(一)
文章配套B站视频,很多话语简略了,建议配着视频看。
地址:https://www.bilibili.com/video/BV13F411P7XB/
开始之前了,简单过一下下面几个方法加深印象,便于更好理解加载器。也可以直接从webpack标题开始看起。
Function/函数/方法
常规的js函数命名方法:
1
2
3
4
5
6
7
8
|
var test = function(){
console.log(123);
}
function test(){
console.log(2);
}
|
今天的主角,自执行函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
!function(){
console.log(1);
}()
!function(e){
console.log(e)
var n={
t:"txt",
exports:{},
n:function(){console.log("function n ")}
}
}("echo this")
!function(e){
console.log(e)
var n={
t:"txt",
exports:{},
n:function(){console.log("function n ")}}
}(
{
"test":function(){
console.log("test")}
}
)
|
call/apply Function
Fcuntion prototype call and applay - JavaScript | MDN](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Function/call))
允许为不同的对象分配和调用属于另一个对象的函数/方法。
call和apply的使用效果基本一致,可以让A对象调用B对象的方法:
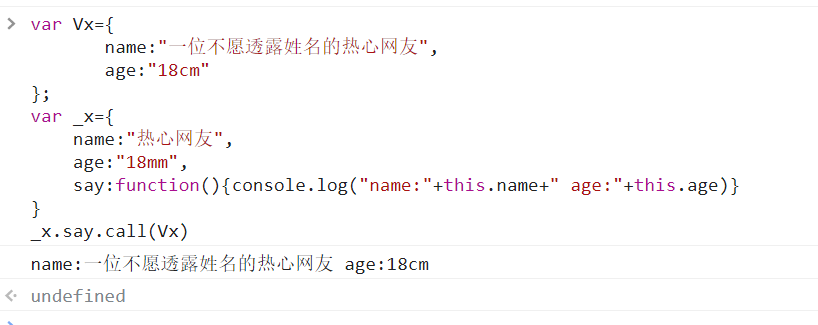
让Vx对象调用_x对象的say()方法
1
2
3
4
5
6
7
8
9
10
11
| var Vx={
name:"一位不愿透露姓名的热心网友",
age:"18cm"
};
var _x={
name:"热心网友",
age:"18mm",
say:function(){console.log("name:"+this.name+" age:"+this.age)}
}
_x.say.call(Vx)
|
Webpack
webpack 一个静态模块打包器,有入口、出口、loader 和插件,通过loader加载器对js、css、图片文件等资源进行加载渲染。
实战站点:https://spa2.scrape.center/
WebPack 站点长什么样
方法1. 右键查看源码发现只会有js链接文件,没有其他多余的前端信息,f12看元素就会有很多数据。
方法2. 看Js文件,一般会有一个app.xxxx.js或长得像MD5的文件名,然后js内容有很多a、b、c、d、n…的变量来回调用,反正就是看着乱。

loader加载器
Webpack站点与普通站点的JS代码扣取是不一样的,因为Webpack站点的资源加载是围绕着加载器进行的,然后把静态资源当作模块传入调用,传入的模块就是参数,需要加载什么就运行什么模块。
先简单看一下加载器长相。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
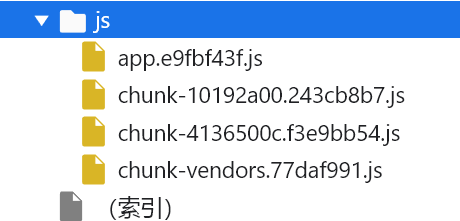
| !function(e){
var t={}
function d(n){
if (t[n])
return t[n].exports;
console.log(n)
var r = t[n] = {
i:n,
l:!1,
exports:{}
};
return e[n].call(r.exports,r,r.exports,d),
r.l = !0;
r.exports
}
d(1)
}(
[
function(){console.log("function1");console.log(this.r.i)},
function(){console.log("function2")}
]
);
|
加载器分析
将加载器拆分为两部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| !function(e){
var t={}
function d(n){
if (t[n])
return t[n].exports;
var r = t[n] = {
i:n,
l:!1,
exports:{}
};
return e[n].call(r.exports,r,r.exports,d),
r.l = !0;
r.exports
}
d(1)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| (
[
function(){console.log("function1");console.log(this.r.i)}
,
function(){console.log("function2")}
]
)
(
{
"1":function(){console.log("function1");console.log(this.r.i)}
,
"2":function(){console.log("function2")}
}
)
|
这里的加载器是将参数作为一个数组【】传入的,格式为:!function(e){}(数组) 参数e就是传入的数组, 接着看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| var t={}
function d(n){
if (t[n])
return t[n].exports;
var r = t[n] = {
i:n,
l:!1,
exports:{}
};
return e[n].call(r.exports,r,r.exports,d),
r.l = !0;
r.exports
}
d(1)
|
上述代码声明了一个d方法并执行,传入1作为参数,d方法中的if (t[n])并没有实际意义,因为t本来就没有声明的,可以缩减为:
1
2
3
4
5
6
7
8
9
10
11
| function d(n){
var r = t[n] = {
i:n,
l:!1,
exports:{}
};
return e[n].call(r.exports,r,r.exports,d),
r.l = !0;
r.exports
}
d(1)
|
那么r=t[n]={ xxxx} 可以变成 var r = { xxx},现在就剩下一句:
return e[n].call(r.exports,r,r.exports,d)
前面说过了,e是传入的参数,也就是数组;n是d(1)传入的值,为1。
r.exports 就是r对象里的exports属性为空对象{}。
转化代码:
1
2
3
4
5
6
7
| return 数组[1].call({},r对象,{},d函数自己)
--> 继续转换:
function(){
console.log("function2")
}.call({},r对象,{},d函数)
|
由于call()方法是用于调用方法的,所以其他参数可以忽略,缩减为:
1
2
3
| function(){
console.log("function2")
}.call(d函数)
|
加载器并没有太多实际的意义,就是自己调用自己,只是用来混淆的;
经过分析后代码可以直接缩减为(当然,只是针对现在这个例子):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| !function(e){
var t={}
console.log("自执行传入的参数是:"+e)
function d(n){
return e[n].call(d)
}
d(1)
}(
[
function(){console.log("function1");console.log()},
function(){console.log("function2")}
]
);
|
分离加载
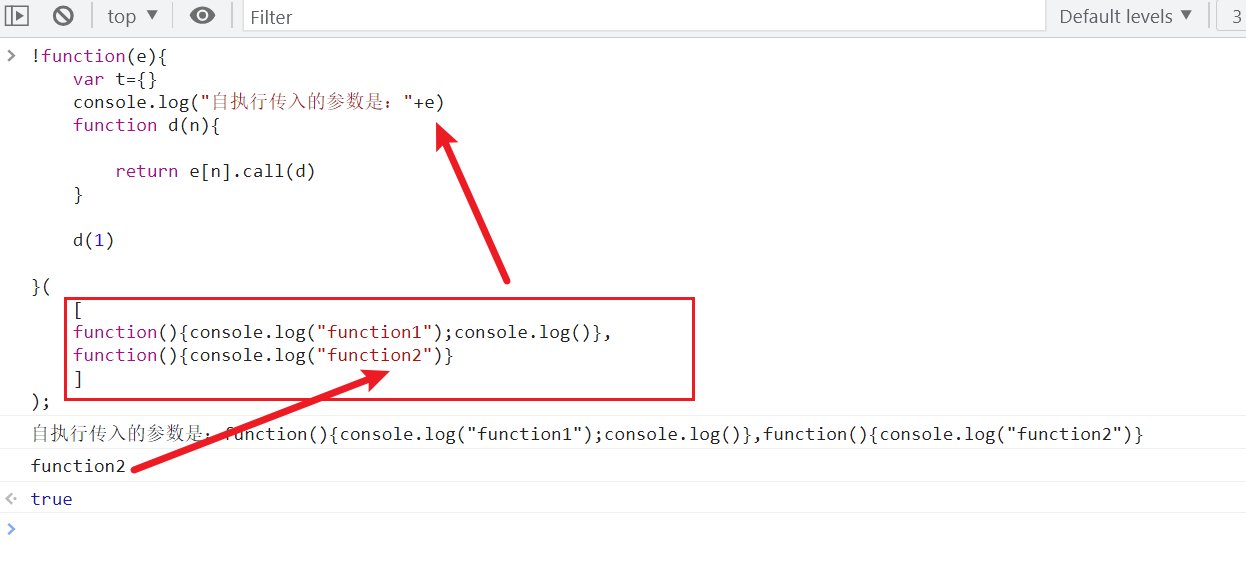
在模块较多的情况下,webpack会将模块打包成一整个JS模块文件;并使用Window对象的webpackJsonp属性存储起来。然后通过push()方法传入模块。
如下:

格式为:
1
2
3
4
5
6
| (window["webpackJsonp"] =
window["webpackJsonp"] || [] ).push([
["xx"], {
"module":function(){}
}
]);
|
运行结果:可以理解为appen追加内容,向webpackJsonp属性追加了[xx],和mod数组
总结
通过两个加载器的两个例子可以看出,加载器的重要性;webpack站点能否成功解析,是围绕着loader加载器和模块资源进行的,加载器好比是一口锅,而模块好似食材;将不一样的食材放入锅中,烹饪的结果都是不一样的。
WebPack实战
分析加密
Webpack站点分析的思路主要以下两点:
首先找到食材,也就是定位到加密模块
其次找到锅,loader加载器
使用加载器去加载模块
在这里的的难点就是定位加密模块,因为调用加密的地方肯定是只有固定的一两个点,如:登录提交。而加载器则什么地方都在调用(网站图片、css、js等资源 都是通过加载器加载出来的)
在上一文《JS逆向|40分钟视频通杀大厂登陆加密》视频中已经讲解了常规加密的快速定位办法,在webpack站点中使用这种定位办法也有概率可能会有效,其实加密点也是有规律的,如:
1
2
3
4
5
6
7
|
xxxxx{
a:e.name,
data:e.data,
b:e.url,
c:n
}
|
这种键值对格式的跟ajax请求长得很相似,有可能是请求赋值的地方,也不绝对,只是大家注意就好。
访问站点右键源码就能发现这是一个webpack网站,数据并不存在于源码之中,是通过XHR获取的JSON数据。
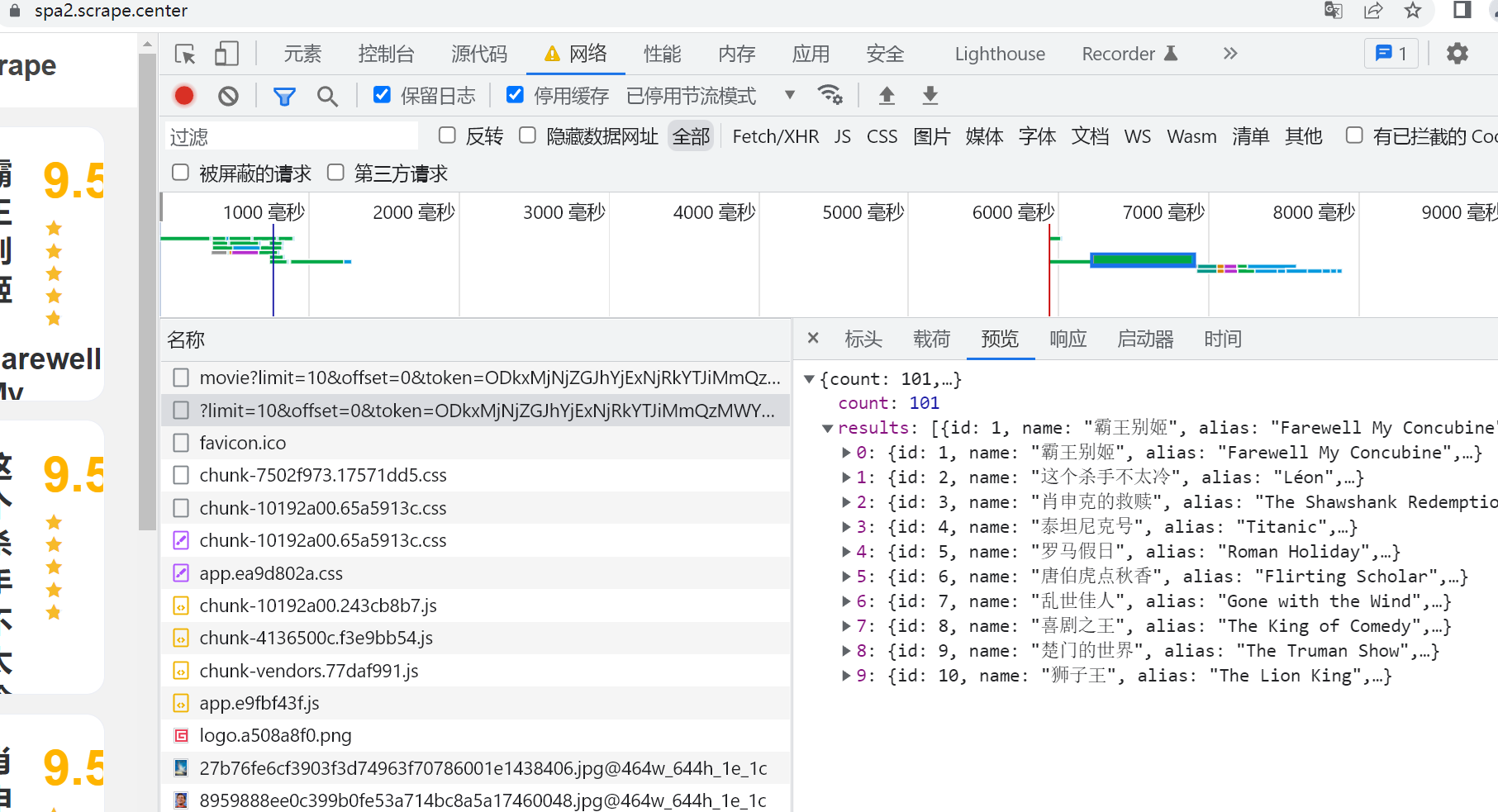
发现是这么一个URL请求的:
1
| https://spa2.scrape.center/api/movie/?limit=10&offset=0&token=ODkxMjNjZGJhYjExNjRkYTJiMmQzMWY3NGY2NTE5YjZlNGIyN2M5YiwxNjU5MzM4MDg4
|
翻页观察发现,limit固定不变,offset每次增加10。两个参数分别是展示的数量与展示的开始位置,token是什么信息暂时未知,但是是必须要解开是。
通过XHR网络断点对所有XHR请求URL进行匹配,只要URL内包含api/movie关键词就进行下断。
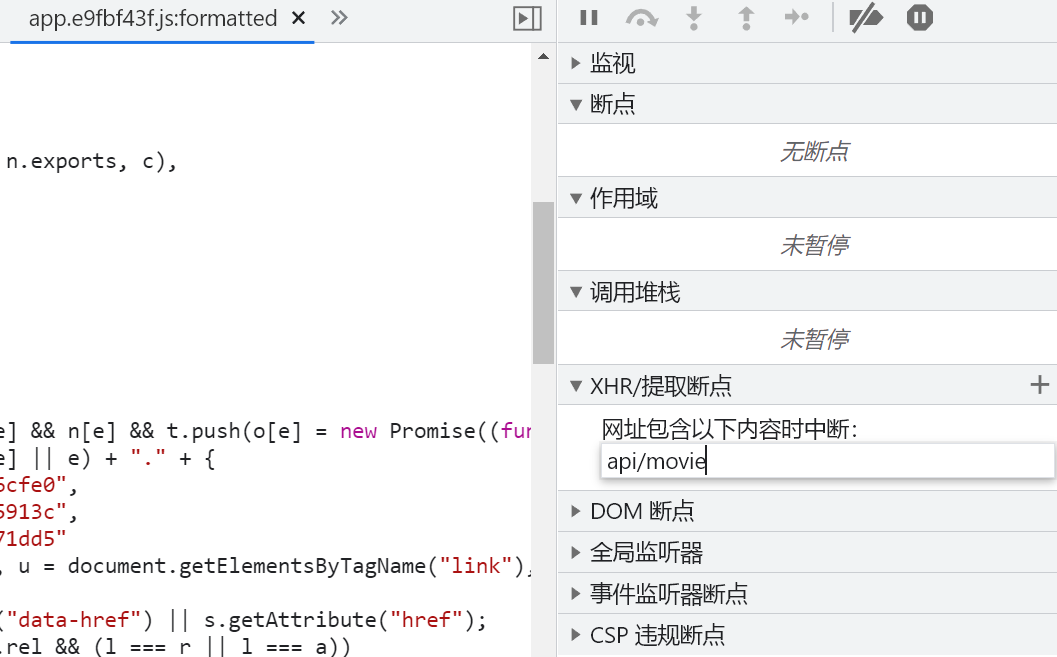
成功断下会展示具体在哪个uRL断的
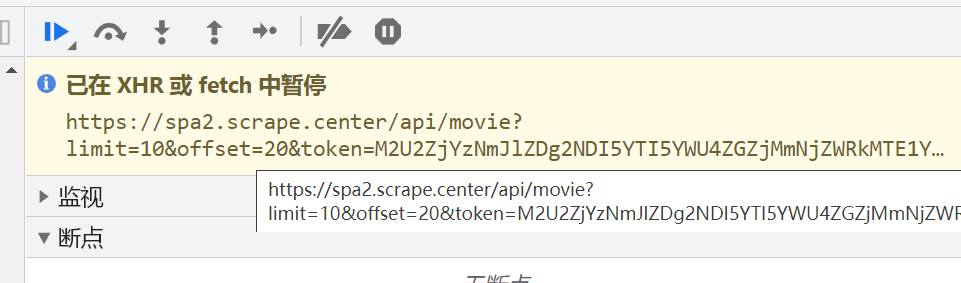
观察堆栈挨个找
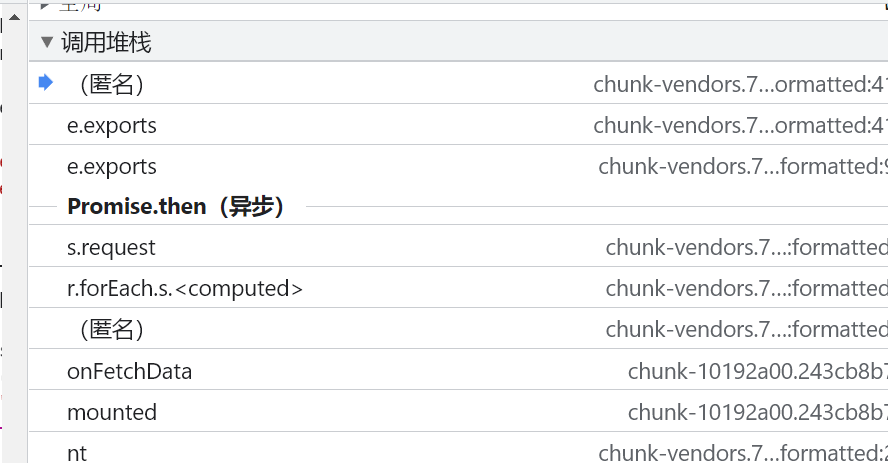
具体找法视频内会详细讲,文字太麻烦了 :sleepy:,一系列操作之后,定位到了加密位置onFetchData:
1
| Object(i["a"])(this.$store.state.url.index, a)
|
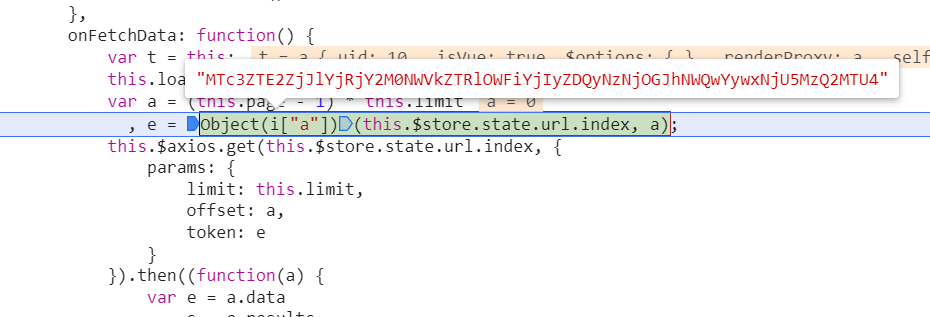
this.$store.state.url.index和e分别是 /api/movie,0(url中的offset翻页值)
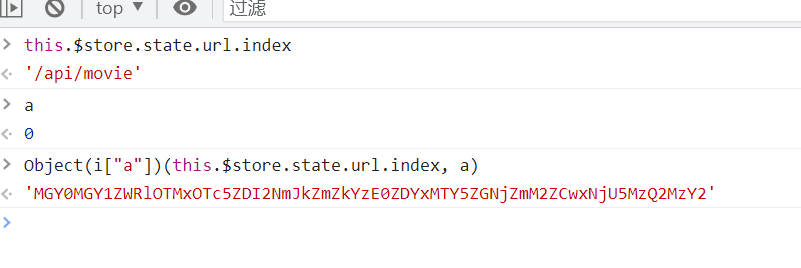
加密算法也就是:Object(i["a"]) 方法
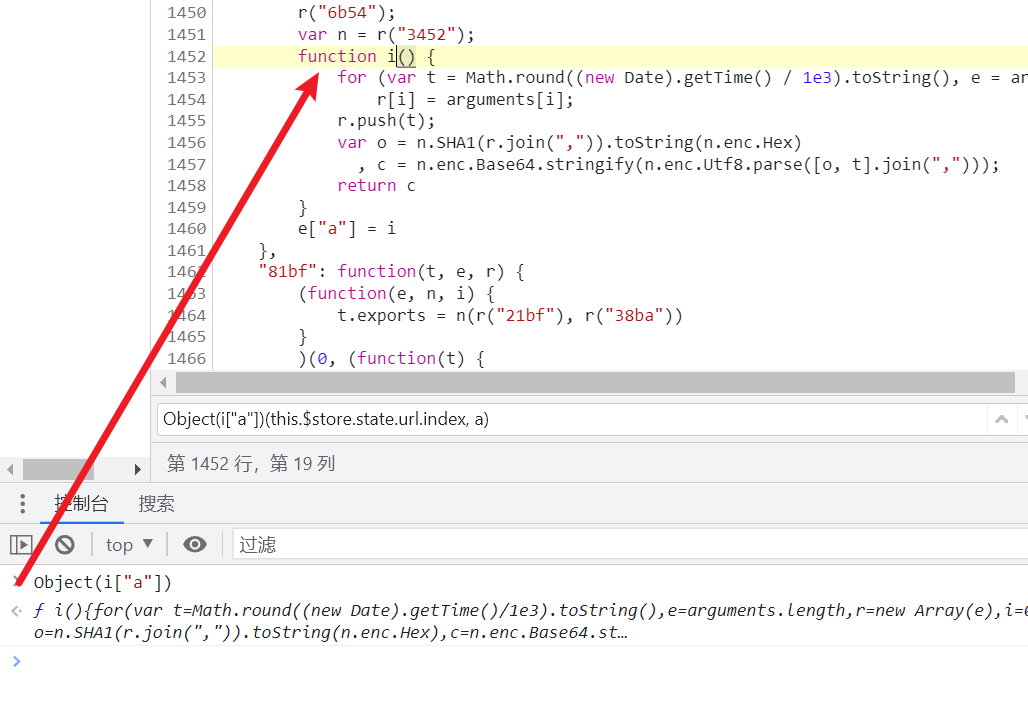
现在把 i() 的内容扣下来就搞定了,但是i方法里有 n的调用
1
2
| var o = n.SHA1(r.join(",")).toString(n.enc.Hex),
c = n.enc.Base64.stringify(n.enc.Utf8.parse([o, t].join(",")));
|
主要就是这两句,n也是我们需要的,查找一下n得值来源,把n也扣取下来
r又是啥?下个断点重新运行看看。
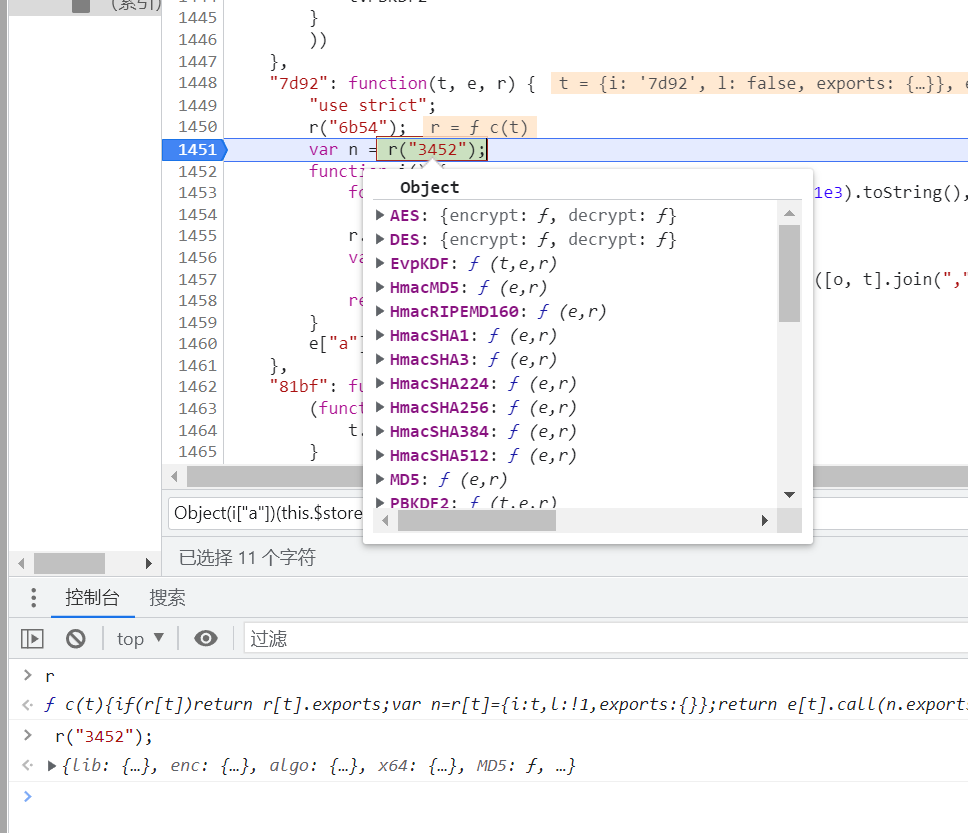
r如果跟过去发现是一个加载器方法:
1
2
3
4
5
6
7
8
9
10
11
12
| function c(t) {
if (r[t])
return r[t].exports;
var n = r[t] = {
i: t,
l: !1,
exports: {}
};
return e[t].call(n.exports, n, n.exports, c),
n.l = !0,
n.exports
}
|
而r("3452") 跟过去,发现很多调用的r(xxx)的
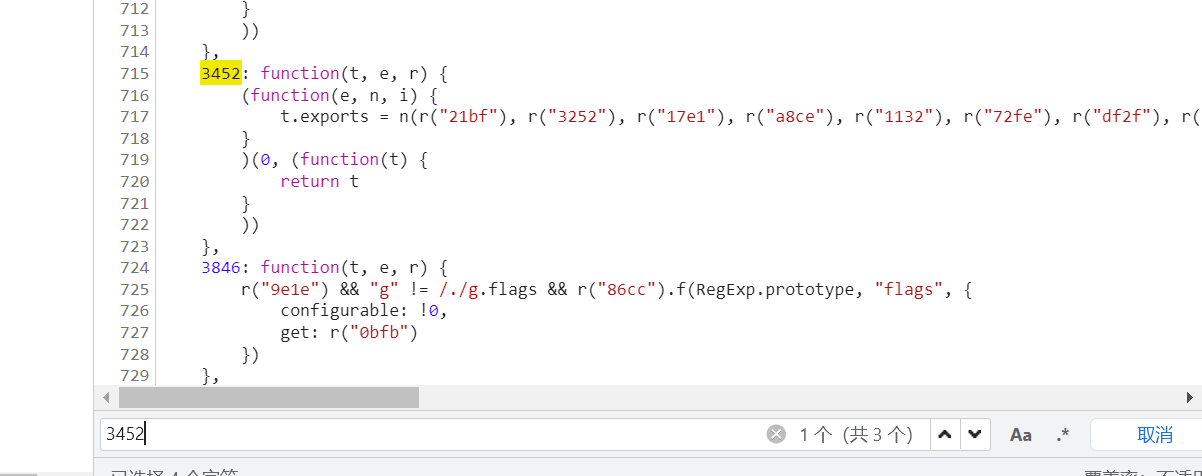
这种情况下很多依赖类调用,如果扣不全很可能缺少某个类从而导致报错无法运行;在依赖少的情况下可以选择缺啥补啥的原则,缺少什么方法就去找什么方法。依赖多的情况下也可以选择把js代码全都摘下来,这样不管有没有用到的方法我代码里都有。但是十几万行代码运行肯定会影响性能,具体优化办法后续会说明的。
扣取代码
由于案例站点依赖比较多,所以只能演示全扣的办法,首先我们把手上的信息整理一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| 加密方法为 :e = Object(i["a"])(this.$store.state.url.index, a);
而 Object(i["a"]) 在“7d29”模块里,为:
function i() {
for (var t = Math.round((new Date).getTime() / 1e3).toString(), e = arguments.length, r = new Array(e), i = 0; i < e; i++)
r[i] = arguments[i];
r.push(t);
var o = n.SHA1(r.join(",")).toString(n.enc.Hex)
, c = n.enc.Base64.stringify(n.enc.Utf8.parse([o, t].join(",")));
return c
}
里面又又n的依赖调用, 为: r("3452");
r 为:加载器
function c(t) {
if (r[t])
return r[t].exports;
var n = r[t] = {
i: t,
l: !1,
exports: {}
};
return e[t].call(n.exports, n, n.exports, c),
n.l = !0,
n.exports
}
“3452"为模块方法:
3452: function(t, e, r) {
(function(e, n, i) {
t.exports = n(r("21bf"), r("3252"), r("17e1"), r("a8ce"), r("1132"), r("72fe"), r("df2f"), r("94f8"), r("191b"), r("d6e6"), r("b86b"), r("e61b"), r("10b7"), r("5980"), r("7bbc"), r("2b79"), r("38ba"), r("00bb"), r("f4ea"), r("aaef"), r("4ba9"), r("81bf"), r("a817"), r("a11b"), r("8cef"), r("2a66"), r("b86c"), r("6d08"), r("c198"), r("a40e"), r("c3b6"), r("1382"), r("3d5a"))
}
)(0, (function(t) {
return t
}
))
}
|
3452模块调用的其他依赖模块太多,直接选择把chunk-4136500c.f3e9bb54.js文件的所有的模块拷贝下来命名为:demo-model1.js, window对象并不存在编译器中,记得var window=global声明一下
把加载器扣出来,然后使用require()导入模块文件,然后设置一个全局变量_c ,将加载器c赋值_c导出运行可以发现报错:
第二个报错提示:at Object.3846 (d:\文稿\Js逆向\demo-model1.js:727:9) 模块文件的727行报错
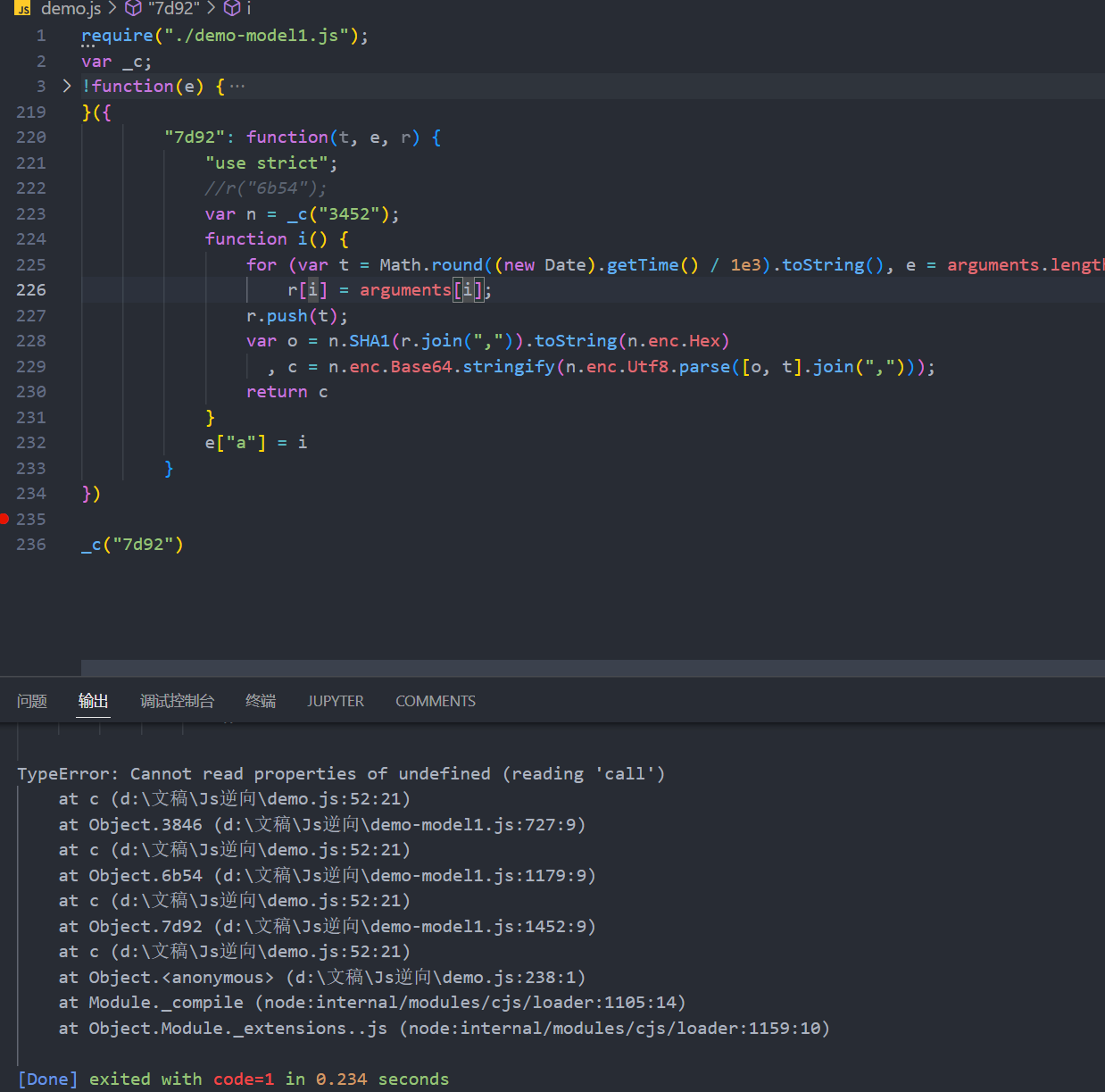
跟过来727行发现又有其他模块调用,应该是缺少了 r("9e1e") 或者r("86cc")导致的报错,
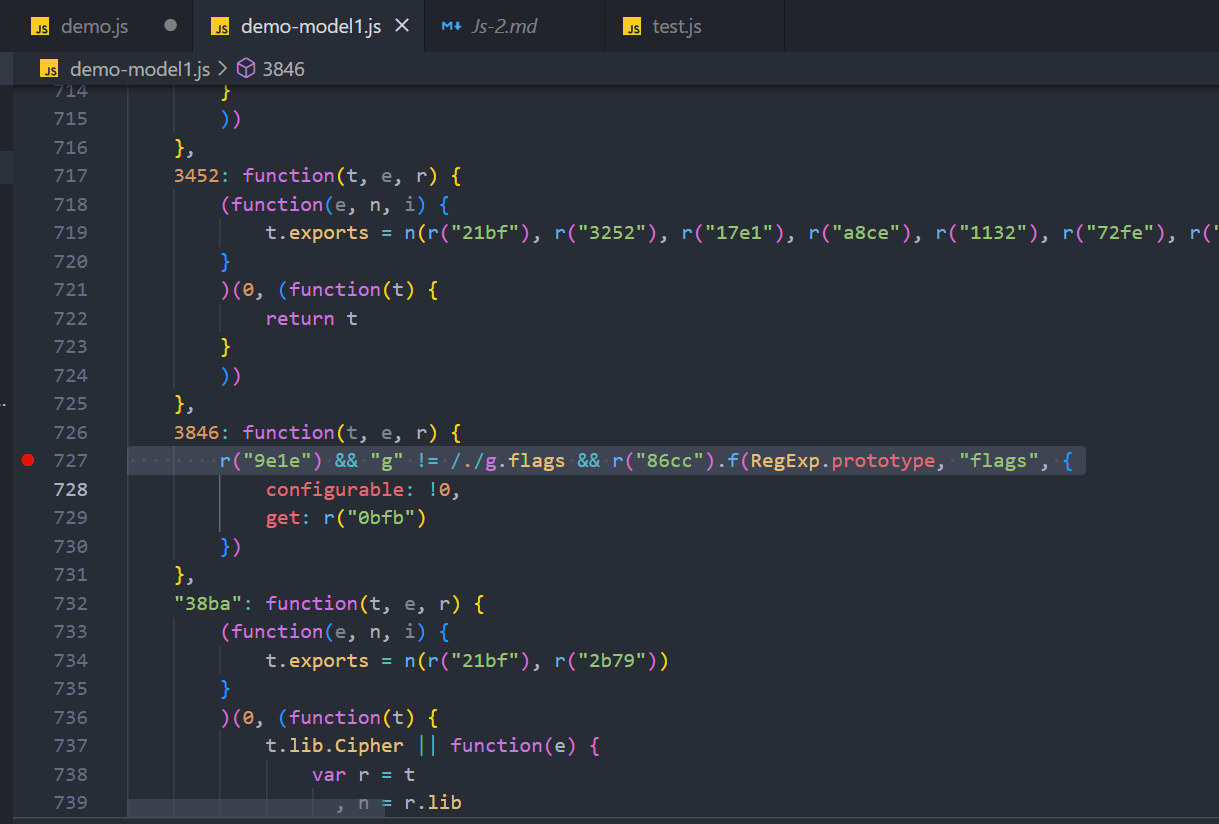
果然搜索也只有一个调用,没有声明的地方。那么又得取扣其他页面代码了。
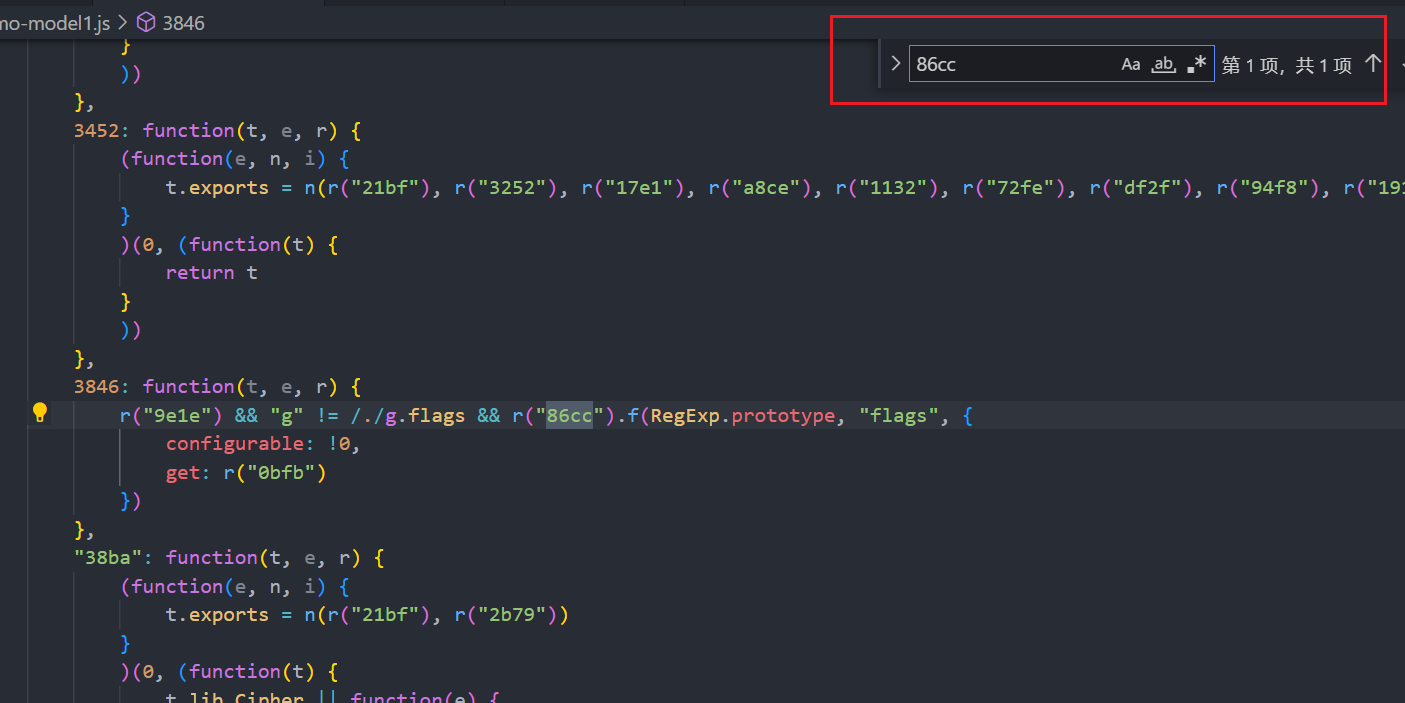
全局搜索网页发现,86cc模块的在chunk-vendors.77daf991.js 文件中被声明了,我们也选择将这文件的所有模块拷贝下来并命名为:demo-module2.js。这两个扣完在编译器中基本也不差模块了,两个js文件全都扣下来了。
自吐算法
上面完整分析了模块与加载器,可谓是你中有我我中有你;由于所有模块都需要经过加载器后调用,所以根据这点特征;可以在调用某个加载模块时,设置一个全局变量,hook所有接下来要调用的模块存储到变量后导出;
hook有一定的局限性,只能到加密方法调用附近进行hook。
1
2
3
4
5
6
| window._load = c;
window._model = t.toString()+":"+(e[t]+"")+ ",";
c = function(t){
window._load = window._load + t.toString()+":"+(e[t]+"")+ ",";
return window._load(t);
}
|
自动化 | Playwright
[Playwright official doc ](Fast and reliable end-to-end testing for modern web apps | Playwright)
站点源码: Burpy|一款流量解密插件 ,在不扣去加密算法时直接就进行爆破:
简单修改一下,将账户和密码都为123的密文放在后台固定写死,如果前端账户和密码都为123就返回密文,不然返回error
安装好Playwright后cmd输入 python -m playwright codegen ,会弹出一个浏览器,访问要爆破的URL。走一遍登录流程后,Playwright会自动生成流程代码。
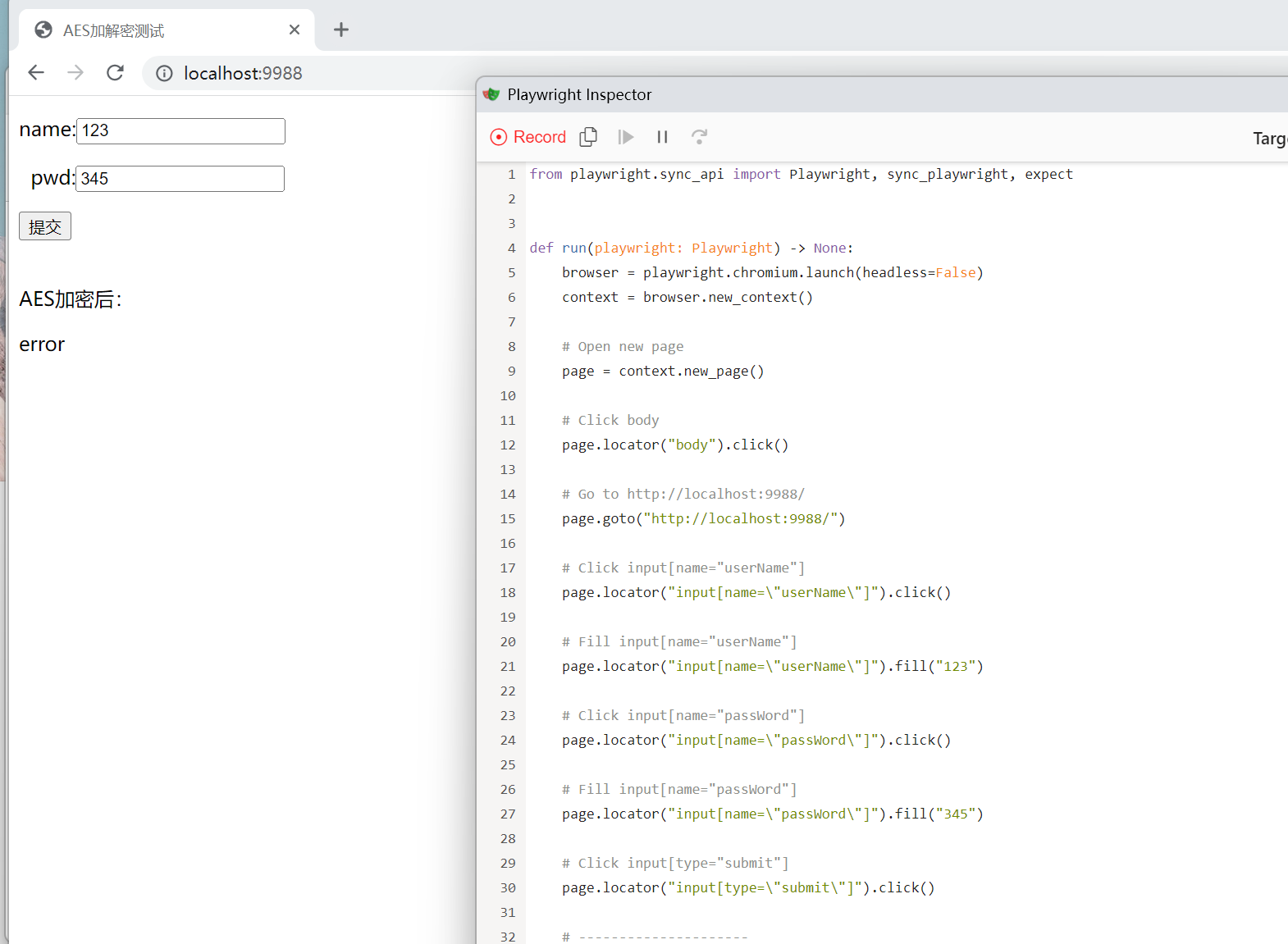
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.locator("body").click()
page.goto("http://localhost:9988/")
page.locator("input[name=\"userName\"]").click()
page.locator("input[name=\"userName\"]").fill("123")
page.locator("input[name=\"passWord\"]").click()
page.locator("input[name=\"passWord\"]").fill("345")
page.locator("input[type=\"submit\"]").click()
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
|
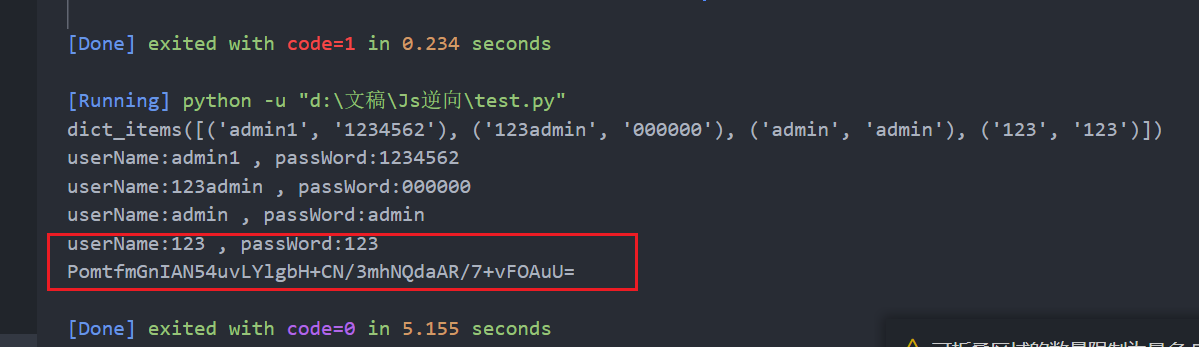
上面代码实现很简单,主要的数据部分就是fill()方法,简单修改一下代码将账户密码变量传入过去,然后做个循环即可。至于判断回显使用page.on()对response进行监听,根据响应长度,密码错误回显为error五个字符长度,大于5则认为成功
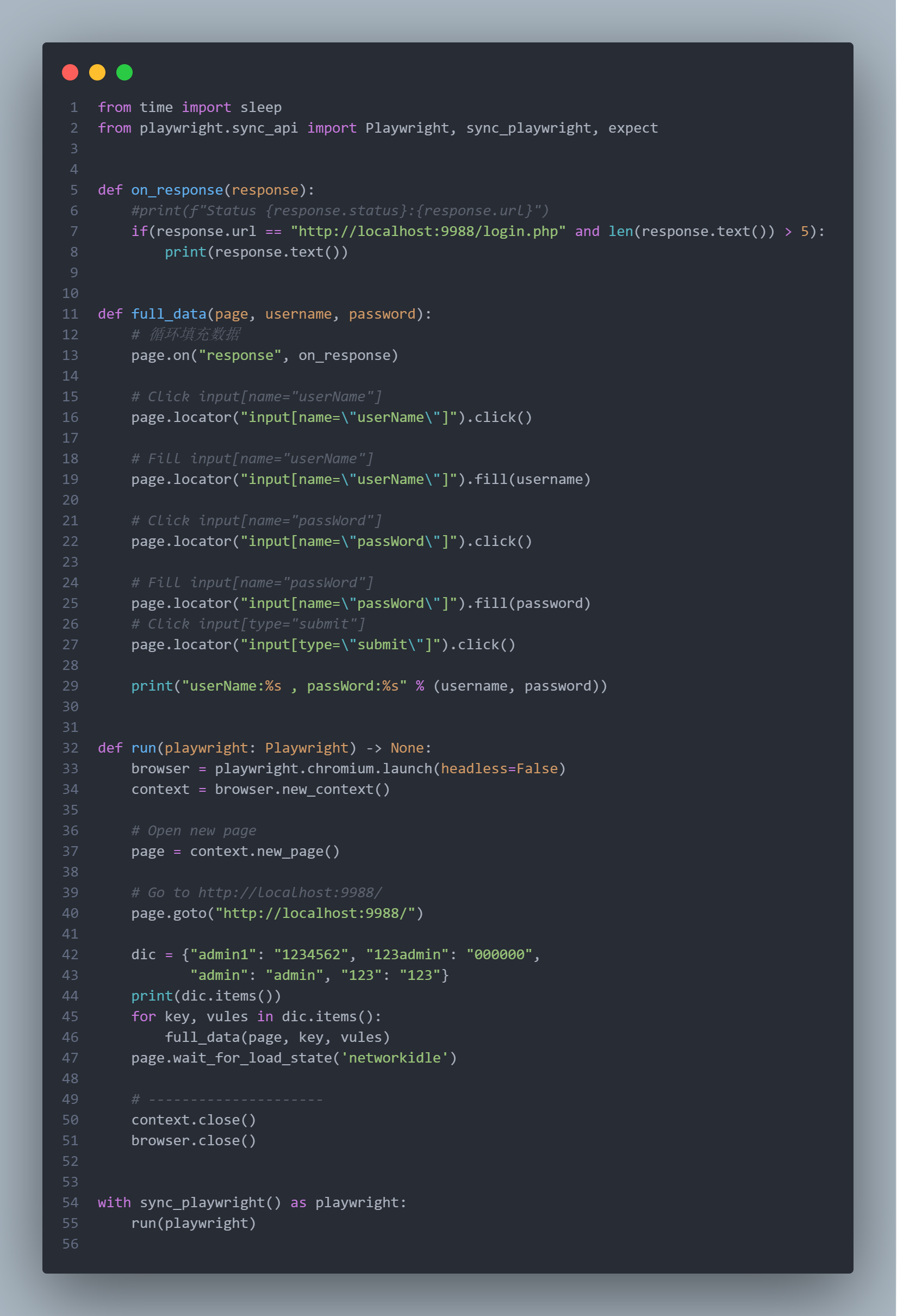
运行结果:账户密码为123,123,加密密文为:PomtfmGnIAN54uvLYlgbH+CN/3mhNQdaAR/7+vFOAuU=
关于接入验证码就不演示了,第三方像超级鹰这类的平台都已经将识别模块打包好,导入简单修改就能用了,网上文章也相当多。